At StudyBits, our mission is to give every learner a private-tutor experience at scale. Behind the screen, that magic is powered by a modular LLM stack that:
- Ingests anything you throw at it — PDFs, slide decks, YouTube links, even phone-snap photos of notes.
- Rips out the knowledge, restructures it, and builds a “Duolingo-style” path (study → practice → review).
- Watches how you perform and adapts in real time.
Below is a peek at three of the design ideas that make this work—minus the proprietary sauce. 🧑🍳
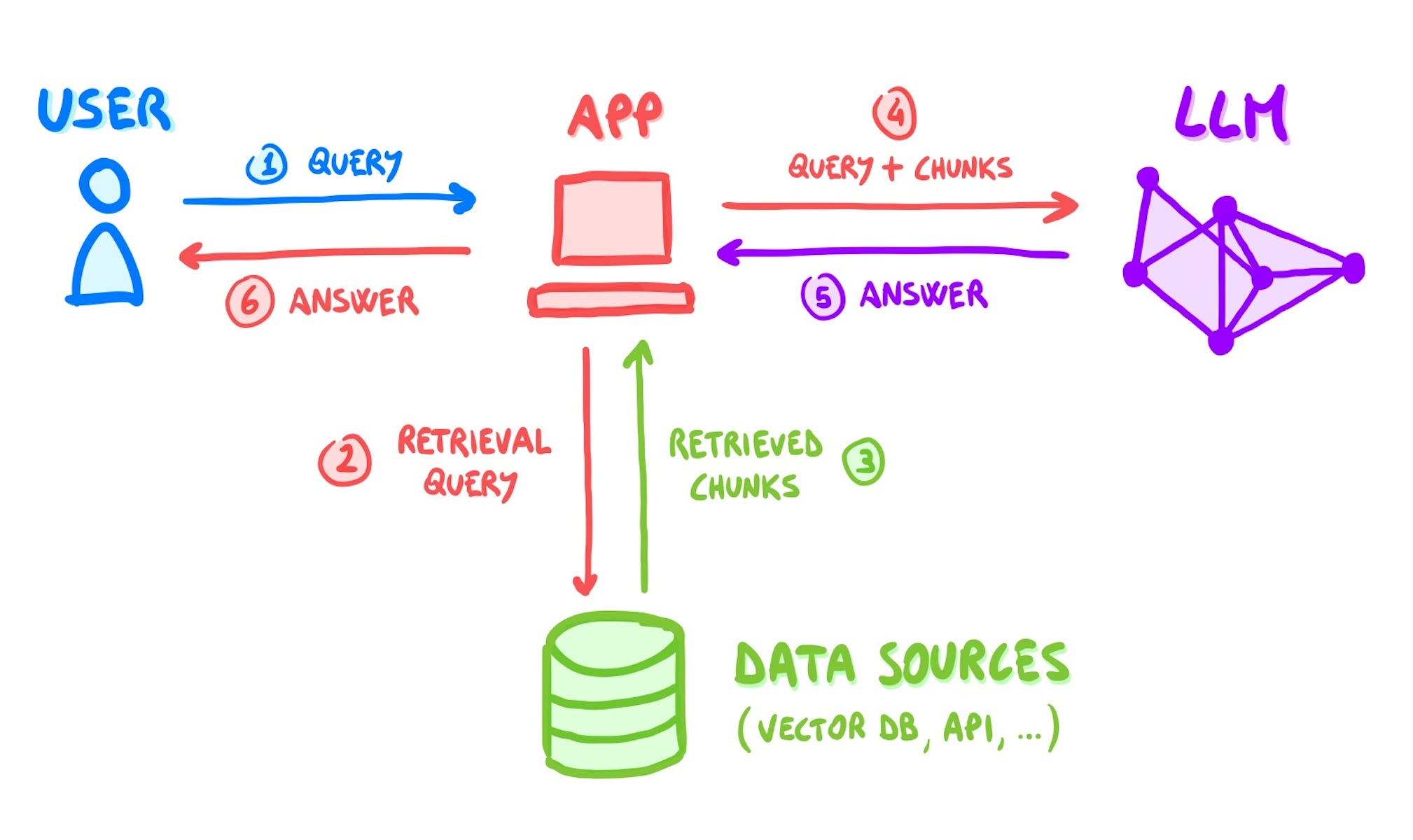
1) 📚 Retrieval-Augmented Generation (RAG) for instant context
Raw transcripts and documents rarely fit inside a single prompt, and fine-tuning every time would be eye-wateringly expensive. Instead we:
- Store chunked embeddings in a vector database.
- At question-time, retrieve only the top-k passages relevant to your current tile.
- Inject those passages into the prompt so the LLM’s answer is grounded in your material, not generic internet mush.
Why this matters: RAG lets us update courses the moment you upload a new chapter and keeps costs roughly 100× lower than full fine-tunes.
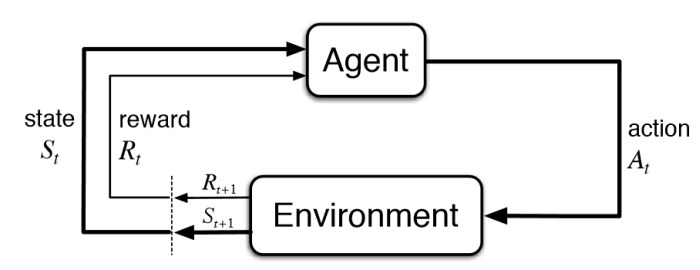
2) 🧠 Reinforcement signals that personalise every click
Each question you answer feeds a tiny reward signal back into an explore-vs-exploit loop:
- If you breeze through logarithms, the engine exploits—advancing faster.
- If you stumble on factoring, it explores nearby algebra gaps before returning to calculus.
- When attention flags (e.g., too many wrong answers in a row) we swap in a different problem type or insert a micro-review.
Early RL-tutoring studies show these policies can cut time-to-mastery by ~30 % without hurting scores.
3) ⚙️ Guardrails for tokens, latency, and cost
LLMs are hungry; eat too fast and you hit rate-limits or blow the budget. We built a few safety nets:
- A sliding-window token bucket keeps every user under OpenAI’s 30 k TPM limit with exponential back-off.
- Chunk-then-merge pipelines hard-split massive PDFs so we never exceed the context cap (128 k tokens per call).
- Proxy rotation & lazy retries for YouTube transcripts ensure success even when transcripts are throttled.
These invisible layers free us to innovate on pedagogy without waking up to a five-figure API bill.
The big picture
LLMs, RAG, and RL aren’t buzzwords for us—they’re the nuts and bolts that shrink the gap between “I want to learn” and “I’m actually learning.” By automating the how of studying, we give back the 37 % of time most students lose deciding what to do next—and even more for learners with ADHD.